

作家先容: 南京大学智能科学与技能学院博士生甘想远为本文第一作家;南京大学高阳讲授为本文互助者;上海东谈主工智能实验室孟林建后生磋商员和南京大学霍静副讲授为本文通信作家。
黑白直播2026世界杯赛事直播入口以 DeepSeek-R1、OpenAI o1 为代表的大型推理模子,凭借长想维链的「想考」智力在数学、代码等任务上大放异彩。但想考是有代价的:冗长、反复的推理经过带来了宏大的推理支出与蔓延,这即是广受良善的「过度想考」(Overthinking)问题。一个当然的处分想路是历练羼杂推理模子:让模子凭证问题难度,自动决定是「三想尔后行」(thinking 花式)如故「无庸婉词」(non-thinking 花式),并使用强化学习(RL)历练模子掌捏这种智力。
然则,这套看似合理的奖励野心,却埋下了一个经典的隐患:奖励骗取(Reward Hacking)。模子很快学会了「钻空子」—— 名义上输出非想考花式的时事标记,实验里却照样进行长篇想考,既靠想考拿到了正确谜底,又骗取了非想考花式的止境奖励。
为了处分这一问题,来自南京大学、上海东谈主工智能实验室和中国移动九天磋商院的磋商团队冷漠了Thinking-Based Non-Thinking(TNT):不依赖昌盛的 SFT,仅摆布想考花式回复中「谜底部分」的长度信息,为每个问题动态设定非想考花式的 token 上限,就将奖励骗取的发生概率压到了 10% 以下,同期在五个数学基准上已毕了准确率与着力的最优量度。
当今,该论文已被当然说话处理顶级会议 ACL 2026 Main Conference 吸收。

论文聚积:https://arxiv.org/abs/2601.04805
代码聚积:https://github.com/SiyuanGan/Thinking-Based_Non-thinking
配景先容:羼杂推理模子与 RL 历练范式
咱们先来总结一下羼杂推理模子的基本设定。
给定一个以额外 token 收尾的输入指示,推理模子的回复率先是想考部分 —— 包含不断探索、反想与自我考据的长想维链; 标记想考截止;自后 则是最终的解答(solution)部分,只包含正确的解题时事与谜底。沿用先前责任的商定,若想考部分为空,则该回复被判定为非想考花式,不然为想考花式。在 RL 历练中,为了饱读吹模子在智力允许时优先选拔高效的非想考花式,正确的非想考回复会被赋予比正确的想考回复更高的奖励。
动机:一个被低估的奖励骗取问题
问题碰劲出在「更高的奖励」上。由于花式判定仅依赖第一个 token 这种名义信号,模子十足不错先输出 伪装成非想考花式,随后的内容却照样反复推演,甚而再次生成 远离符 —— 靠实在的想考得到正确谜底,却领走了非想考花式的高额奖励。

奖励骗取问题示例。模子生成的首个 token 为 ,被分类为 non-thinking 花式,但回复内容昭着具有 thinking 花式特征(如使用 "Wait"、"Alternatively" 等要道词),组成了典型的奖励骗取活动。
这一问题的严重性超出联想。著述实测发现,未处理奖励骗取的 RL 法子在 AIME24 上,被判定为「非想考花式」的回复平均 token 用量竟高达 10845,与想考花式的 11976 险些不相高下 —— 所谓的「非想考」已名存实一火,统统这个词历练事实上依然坍塌。
针对该问题,现存决策或者有两条路,但各有硬伤:其一是引入 SFT 来固定模子两种花式的输出行,但 SFT 计较支出极其昌盛;更糟的是,开云体育SFT 还会带来显耀的性能退化,先前责任的 SFT 模子在 AIME24 上准确率仅约 10%。其二是为非想考花式设定最大 token 上限,超限即视为骗取,但现存责任对统统问题施加调和的上限,这在逻辑上是行欠亨的:通俗问题(如「1+1 等于几」)即便用长想维链反复考据,其 token 数也可能远低于复杂 AIME 题目日常作答的长度。
法子:
用想考花式的「谜底」
标定非想考花式的「尺子」
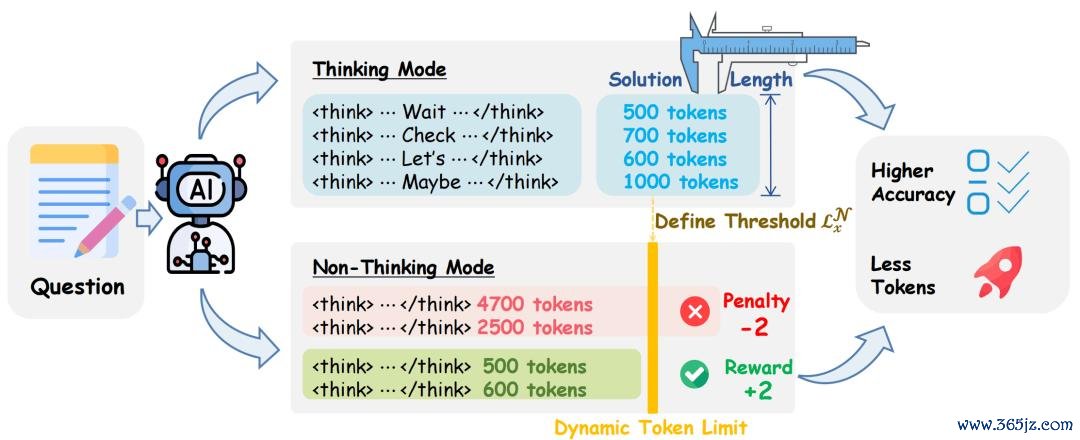
图 1:TNT 法子概览。
破局的要道洞见相等优雅:想考花式回复中 之后的解答部分,自己就不含想考 —— 而这恰好就利害想考花式的界说。换言之,想考花式回复自带一份「该问题的谜底日常应该写多长」的免费标尺。TNT 恰是摆布这少许,为每个问题动态设定非想考花式的 token 上限。

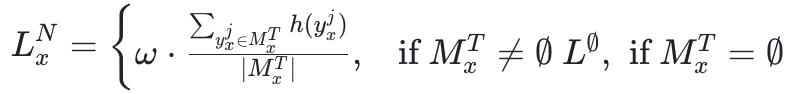


整套法子基于 GRPO 进行历练,无需任何 SFT,无需修改模子结构或 tokenizer,况且与 Dr. GRPO、DAPO、GSPO 乃至经典 PPO 等算法自然兼容,是一个即插即用的奖励层面修正。
实验考据:准确率与着力的双赢
著述以 DeepSeek-R1-Distill-Qwen-1.5B/7B 和 DeepScaleR-1.5B 为基座模子进行了实验的考据。
更少的 token,更高的准确率。在 1.5B 模子上,TNT 比较基座模子将平均 token 用量削减 46.2%,平均准确率反而擢升 4.1 个百分点,卓越一皆同类法子设置。
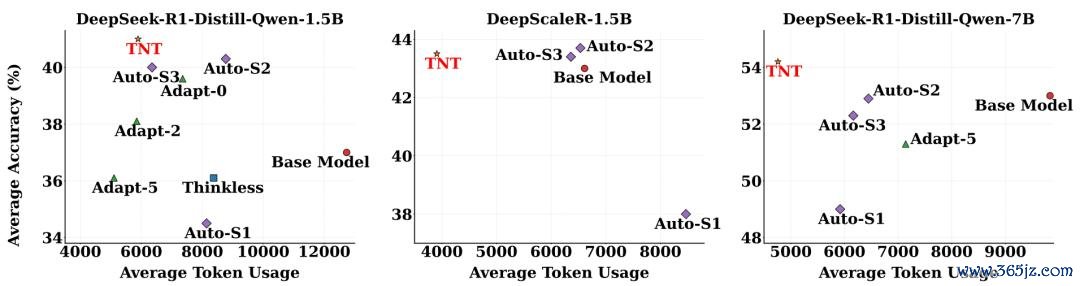
不同羼杂推理模子历练法子在数学基准上的平均准确率与 token 用量对比。
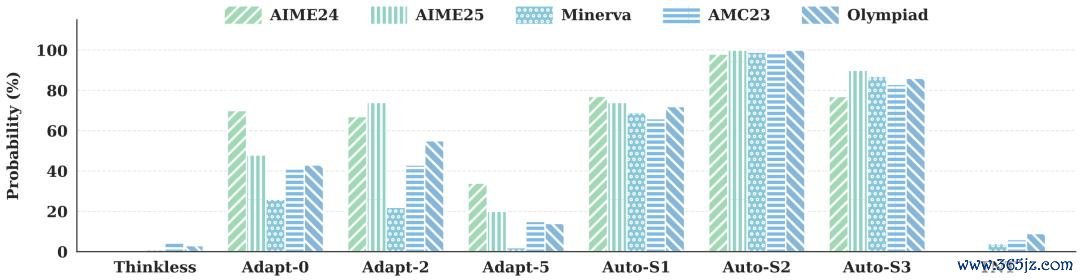
各模子在 non-thinking 花式回复中出现 thinking 相关动词的概率。
奖励骗取被灵验装潢。著述统计了非想考花式回复中「Wait」、「Alternatively」等想考类动词的出现概率:未琢磨该问题的 AutoThink 概率最高,经受调和上限的 AdaptThink 也显耀偏高,而 TNT 在统统测试集上均低于 10%,仅次于付出了昌盛 SFT 代价的法子。
模子学会了「看菜下饭」。TNT 的非想考花式占比与任务难度呈明晰的负相关:在 AIME24/25 这类费事上险些全程想考(占比仅 1.7%/0.8%),在相对通俗的 AMC23 上则有近 30% 的问题平直作答,已毕了基于难度的自主花式选拔。
基座越强,上风越大。在 DeepScaleR-1.5B 与 7B 模子上,TNT 的 TE 永诀达到 0.70 与 0.79,大幅跳跃次优法子的 0.54 与 0.67;在 7B 上更是同期拿下最高平均准确率(54.2%)与最低 token 用量。此外,TNT 在与 CoT 压缩法子的对比中全面胜出,并在 GPQA Diamond 这一散布外基准上获取最优成果,展现了雅致的泛化性。
总结和瞻望
一言以蔽之,这篇论文直面了羼杂推理模子 RL 历练中一个具体而致命的失效花式,奖励骗取,并给出了一个四两拨千斤的解法:与其用昌盛的 SFT 去「管住」模子的输出,或用一刀切的上限去「猜」每谈题的合理长度,不如让想考花式我方的解答部分来告诉咱们,这谈题不想考时日常应该写多长。由此冷漠的 TNT 无需 SFT、无需变调模子结构开云体育(kaiyun)官网,仅在奖励层面引入一个动态 token 上限,便在三个基座模子、五个数学基准上一致地已毕了约 50% 的 token 削减与准确率擢升,并将奖励骗取概率压制在 10% 以内。
 备案号:
备案号: